All leaked interview problems are collected from Internet.
169. Majority Element
Given an array of size n, find the majority element. The majority element is the element that appears more than ⌊ n/2 ⌋ times.
You may assume that the array is non-empty and the majority element always exist in the array.
Credits:
Special thanks to @ts for adding this problem and creating all test cases.
b'
Approach #1 Brute Force [Time Limit Exceeded]
\nIntuition
\nWe can exhaust the search space in quadratic time by checking whether each\nelement is the majority element.
\nAlgorithm
\nThe brute force algorithm iterates over the array, and then iterates again\nfor each number to count its occurrences. As soon as a number is found to\nhave appeared more than any other can possibly have appeared, return it.
\n\nComplexity Analysis
\n- \n
- \n
Time complexity : \n
\nThe brute force algorithm contains two nested
\nforloops that each run\nfor iterations, adding up to quadratic time complexity. \n - \n
Space complexity : \n
\nThe brute force solution does not allocate additional space proportional\nto the input size.
\n \n
\n
Approach #2 HashMap [Accepted]
\nIntuition
\nWe know that the majority element occurs more than \ntimes, and a HashMap allows us to count element occurrences efficiently.
Algorithm
\nWe can use a HashMap that maps elements to counts in order to count\noccurrences in linear time by looping over nums. Then, we simply return the\nkey with maximum value.
Complexity Analysis
\n- \n
- \n
Time complexity : \n
\nWe iterate over
\nnumsonce and make a constant timeHashMapinsertion\non each iteration. Therefore, the algorithm runs in time. \n - \n
Space complexity : \n
\nAt most, the
\nHashMapcan contain \nassociations, so it occupies space. This is because an arbitrary\narray of length can contain distinct values, butnumsis\nguaranteed to contain a majority element, which will occupy (at minimum)\n array indices. Therefore,\n indices can be occupied by\ndistinct, non-majority elements (plus 1 for the majority element itself),\nleaving us with (at most) distinct\nelements. \n
\n
Approach #3 Sorting [Accepted]
\nIntuition
\nIf the elements are sorted in monotonically increasing (or decreasing) order,\nthe majority element can be found at index\n (and ,\nincidentally, if is even).
\nAlgorithm
\nFor this algorithm, we simply do exactly what is described: sort nums, and\nreturn the element in question. To see why this will always return the\nmajority element (given that the array has one), consider the figure below\n(the top example is for an odd-length array and the bottom is for an\neven-length array):
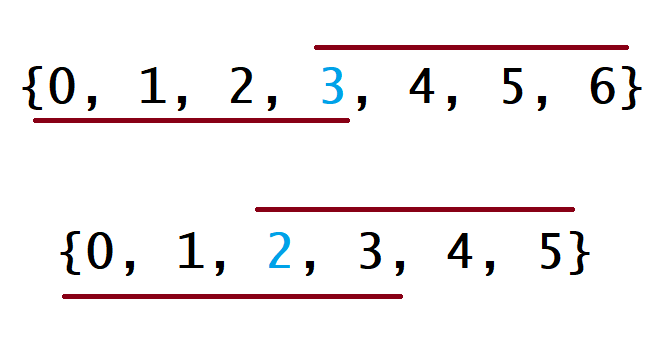
For each example, the line below the array denotes the range of indices that\nare covered by a majority element that happens to be the array minimum. As\nyou might expect, the line above the array is similar, but for the case where\nthe majority element is also the array maximum. In all other cases, this line\nwill lie somewhere between these two, but notice that even in these two most\nextreme cases, they overlap at index for both\neven- and odd-length arrays. Therefore, no matter what value the majority\nelement has in relation to the rest of the array, returning the value at\n will never be wrong.
\n\nComplexity Analysis
\n- \n
- \n
Time complexity : \n
\nSorting the array costs time in Python and Java, so it\ndominates the overall runtime.
\n \n - \n
Space complexity : or (\n
\nWe sorted
\nnumsin place here - if that is not allowed, then we must\nspend linear additional space on a copy ofnumsand sort the copy\ninstead. \n
\n
Approach #4 Randomization [Accepted?]
\nIntuition
\nBecause more than array indices are occupied\nby the majority element, a random array index is likely to contain the\nmajority element.
\nAlgorithm
\nBecause a given index is likely to have the majority element, we can just\nselect a random index, check whether its value is the majority element,\nreturn if it is, and repeat if it is not. The algorithm is verifiably correct\nbecause we ensure that the randomly chosen value is the majority element\nbefore ever returning.
\n\nComplexity Analysis
\n- \n
- \n
Time complexity : \n
\nIt is technically possible for this algorithm to run indefinitely (if we\nnever manage to randomly select the majority element), so the worst\npossible runtime is unbounded. However, the expected runtime is far\nbetter - linear, in fact. For ease of analysis, convince yourself that\nbecause the majority element is guaranteed to occupy more than half of\nthe array, the expected number of iterations will be less than it would\nbe if the element we sought occupied exactly half of the array.\nTherefore, we can calculate the expected number of iterations for this\nmodified version of the problem and assert that our version is easier.
\n\n\n
\nBecause the series converges, the expected number of iterations for the\nmodified problem is constant. Based on an expected-constant number of\niterations in which we perform linear work, the expected runtime is\nlinear for the modifed problem. Therefore, the expected runtime for our\nproblem is also linear, as the runtime of the modifed problem serves as\nan upper bound for it.
\n \n - \n
Space complexity : \n
\nMuch like the brute force solution, the randomized approach runs with\nconstant additional space.
\n \n
\n
Approach #5 Divide and Conquer [Accepted]
\nIntuition
\nIf we know the majority element in the left and right halves of an array, we\ncan determine which is the global majority element in linear time.
\nAlgorithm
\nHere, we apply a classical divide & conquer approach that recurses on the\nleft and right halves of an array until an answer can be trivially achieved\nfor a length-1 array. Note that because actually passing copies of subarrays\ncosts time and space, we instead pass lo and hi indices that describe the\nrelevant slice of the overall array. In this case, the majority element for a\nlength-1 slice is trivially its only element, so the recursion stops there.\nIf the current slice is longer than length-1, we must combine the answers for\nthe slice\'s left and right halves. If they agree on the majority element,\nthen the majority element for the overall slice is obviously the same1. If\nthey disagree, only one of them can be "right", so we need to count the\noccurrences of the left and right majority elements to determine which\nsubslice\'s answer is globally correct. The overall answer for the array is\nthus the majority element between indices 0 and .
Complexity Analysis
\n- \n
- \n
Time complexity : \n
\nEach recursive call to
\nmajority_element_recperforms two recursive\ncalls on subslices of size and two linear scans of length\n. Therefore, the time complexity of the divide & conquer approach\ncan be represented by the following recurrence relation:\n\n
\nBy the master theorem,\nthe recurrence satisfies case 2, so the complexity can be analyzed as such:
\n\n\n
\n \n - \n
Space complexity : \n
\nAlthough the divide & conquer does not explicitly allocate any additional\nmemory, it uses a non-constant amount of additional memory in stack\nframes due to recursion. Because the algorithm "cuts" the array in half\nat each level of recursion, it follows that there can only be \n"cuts" before the base case of 1 is reached. It follows from this fact\nthat the resulting recursion tree is balanced, and therefore all paths\nfrom the root to a leaf are of length . Because the recursion\ntree is traversed in a depth-first manner, the space complexity is\ntherefore equivalent to the length of the longest path, which is, of\ncourse, .
\n \n
\n
Approach #6 Boyer-Moore Voting Algorithm [Accepted]
\nIntuition
\nIf we had some way of counting instances of the majority element as \nand instances of any other element as , summing them would make it\nobvious that the majority element is indeed the majority element.
\nAlgorithm
\nEssentially, what Boyer-Moore does is look for a suffix of nums\nwhere is the majority element in that suffix. To do this, we\nmaintain a count, which is incremented whenever we see an instance of our\ncurrent candidate for majority element and decremented whenever we see\nanything else. Whenever count equals 0, we effectively forget about\neverything in nums up to the current index and consider the current number\nas the candidate for majority element. It is not immediately obvious why we can\nget away with forgetting prefixes of nums - consider the following\nexamples (pipes are inserted to separate runs of nonzero count).
[7, 7, 5, 7, 5, 1 | 5, 7 | 5, 5, 7, 7 | 7, 7, 7, 7]
\nHere, the 7 at index 0 is selected to be the first candidate for majority\nelement. count will eventually reach 0 after index 5 is processed, so the\n5 at index 6 will be the next candidate. In this case, 7 is the true\nmajority element, so by disregarding this prefix, we are ignoring an equal\nnumber of majority and minority elements - therefore, 7 will still be the\nmajority element in the suffix formed by throwing away the first prefix.
[7, 7, 5, 7, 5, 1 | 5, 7 | 5, 5, 7, 7 | 5, 5, 5, 5]
\nNow, the majority element is 5 (we changed the last run of the array from\n7s to 5s), but our first candidate is still 7. In this case, our\ncandidate is not the true majority element, but we still cannot discard more\nmajority elements than minority elements (this would imply that count could\nreach -1 before we reassign candidate, which is obviously false).
Therefore, given that it is impossible (in both cases) to discard more\nmajority elements than minority elements, we are safe in discarding the\nprefix and attempting to recursively solve the majority element problem for the\nsuffix. Eventually, a suffix will be found for which count does not hit\n0, and the majority element of that suffix will necessarily be the same as\nthe majority element of the overall array.
Complexity Analysis
\n- \n
- \n
Time complexity : \n
\nBoyer-Moore performs constant work exactly times, so the algorithm\nruns in linear time.
\n \n - \n
Space complexity : \n
\nBoyer-Moore allocates only constant additional memory.
\n \n
\n
Footnotes
\n\n
Analysis written by: @emptyset
\nApproaches and time complexities itemized by @ts and @1337c0d3r
\n\n
- \n
- \n
This is a constant optimization that could be excluded without hurting our\n overall runtime.\xc2\xa0\xe2\x86\xa9
\n \n