All leaked interview problems are collected from Internet.
645. Set Mismatch
The set S originally contains numbers from 1 to n. But unfortunately, due to the data error, one of the numbers in the set got duplicated to another number in the set, which results in repetition of one number and loss of another number.
Given an array nums representing the data status of this set after the error. Your task is to firstly find the number occurs twice and then find the number that is missing. Return them in the form of an array.
Example 1:
Input: nums = [1,2,2,4] Output: [2,3]
Note:
- The given array size will in the range [2, 10000].
- The given array's numbers won't have any order.
b'
- \n
- Solution\n \n
Solution
\nApproach #1 Brute Force [Time Limit Exceeded]
\nThe most naive solution is to consider each number from to , and traverse over the whole array to check if the current number occurs twice in \nor doesn\'t occur at all. We need to set the duplicate number, and the missing number, , appropriately in such cases respectively.
\n\nComplexity Analysis
\n- \n
- \n
Time complexity : . We traverse over the array of size for each of the numbers from to .
\n \n - \n
Space complexity : . Constant extra space is used.
\n \n
\n
Approach #2 Better Brute Force [Time Limit Exceeded]
\nIn the last approach, we continued the search process, even when we\'ve already found the duplicate and the missing number. But, as per the problem statement, \nwe know that only one number will be repeated and only one number will be missing. Thus, we can optimize the last approach to some extent, by stopping \nthe search process as soon as we find these two required numbers.
\n\nComplexity Analysis
\n- \n
- \n
Time complexity : . We traverse over the array of size for each of the numbers from to , in the worst case.
\n \n - \n
Space complexity : . Constant extra space is used.
\n \n
\n
Approach #3 Using Sorting [Accepted]
\nAlgorithm
\nOne way to further optimize the last approach is to sort the given array. This way, the numbers which are equal will always lie together. \nFurther, we can easily identify the missing number by checking if every two consecutive elements in the sorted array are just one count apart or not.
\n\nComplexity Analysis
\n- \n
- \n
Time complexity : . Sorting takes time.
\n \n - \n
Space complexity : . Sorting takes space.
\n \n
\n
Approach #4 Using map [Accepted]
\nAlgorithm
\nThe given problem can also be solved easily if we can somehow keep a track of the number of times each element of the array occurs. One way to \ndo so is to make an entry for each element of in a HashMap . This stores the entries in the form . Here, refers to\nthe element in and refers to the number of times this element occurs in .\n Whenever, the same element occurs again, we can increment the count corresponding to the \nsame.
\nAfter this, we can consider every number from to , and check for its presence in . If it isn\'t present, we can update the variable \nappropriately. But, if the corresponding to the current number is , we can update the variable with the current number.
\n\nComplexity Analysis
\n- \n
- \n
Time complexity : . Traversing over of size takes time. Considering each number from to also takes time.
\n \n - \n
Space complexity : . can contain atmost entries for each of the numbers from to .
\n \n
\n
Approach #5 Using Extra Array[Accepted]:
\nAlgorithm
\nIn the last approach, we make use of a to store the elements of along with their corresponding counts. But, we can note, that each entry in \nrequires two entries. Thus, putting up entries requires space actually. We can reduce this space required to by making use of an array, instead.\nNow, the indices of can be used instead of storing the elements again. Thus, we make use of in such a way that, is used to store \nthe number of occurences of the element . The rest of the process remains the same as in the last approach.
\n\nComplexity Analysis
\n- \n
- \n
Time complexity : . Traversing over of size takes time. Considering each number from to also takes time.
\n \n - \n
Space complexity : . can contain atmost elements for each of the numbers from to .
\n \n
\n
Approach #6 Using Constant Space[Accepted]:
\nAlgorithm
\nWe can save the space used in the last approach, if we can somehow, include the information regarding the duplicacy of an element or absence of an element\n in the array. Let\'s see how this can be done.
\nWe know that all the elements in the given array are positive, and lie in the range to only. Thus, we can pick up each element \n from . For every number picked up, we can invert the element at the index . By doing so, if one of the elements occurs twice, \nwhen this number is encountered the second time, the element will be found to be negative. \nThus, while doing the inversions, we can check if a number found is already negative, to find the duplicate number.
\nAfter the inversions have been done, if all the elements in are present correctly, the resultant array will have all the elements as \n negative now. But, if one of the numbers, is missing, the element at the index will be positive. This can be used to determine the missing number.
\n\nComplexity Analysis
\n- \n
- \n
Time complexity : . Two traversals over the array of size are done.
\n \n - \n
Space complexity : . Constant extra space is used.
\n \n
\n
Approach #7 Using XOR [Accepted]:
\nAlgorithm
\nBefore we dive into the solution to this problem, let\'s consider a simple problem. Consider an array with elements containing numbers from to with one number missing out of them. Now, how to we find out this missing element. One of the solutions is to take the XOR of all the elements of this array with all the numbers from to . By doing so, we get the required missing number. This works because XORing a number with itself results in a 0 result. Thus, only the number which is missing can\'t get cancelled with this XORing.
\nNow, using this idea as the base, let\'s take it a step forward and use it for the current problem. By taking the XOR of all the elements of the given array with all the numbers from to , we will get a result, , as . Here, and refer to the repeated and the missing term in the given array. This happens on the same grounds as in the first problem discussed above.
\nNow, in the resultant , we\'ll get a 1 in the binary representation only at those bit positions which have a 1 in one out of the numbers and , and a 0 at the same bit position in the other one. In the current solution, we consider the rightmost bit which is 1 in the , although any bit would work. Let\'s say, this position is called the .
\nIf we divide the elements of the given array into two parts such that the first set contains the elements which have a 1 at the position and the second set contains the elements having a 0 at the same position, we\'ll get one out of or in one set and the other one in the second set. Now, our problem has reduced somewhat to the simple problem discussed above.
\nTo solve this reduced problem, we can find out the elements from to and consider them as a part of the previous sets only, with the allocation of the set depending on a 1 or 0 at the position.
\nNow, if we do the XOR of all the elements of the first set, all the elements will result in an XOR of 0, due to cancellation of the similar terms in both and the numbers , except one term, which is either or .
\nFor the other term, we can do the XOR of all the elements in the second set as well.
\nConsider the example [1 2 4 4 5 6]
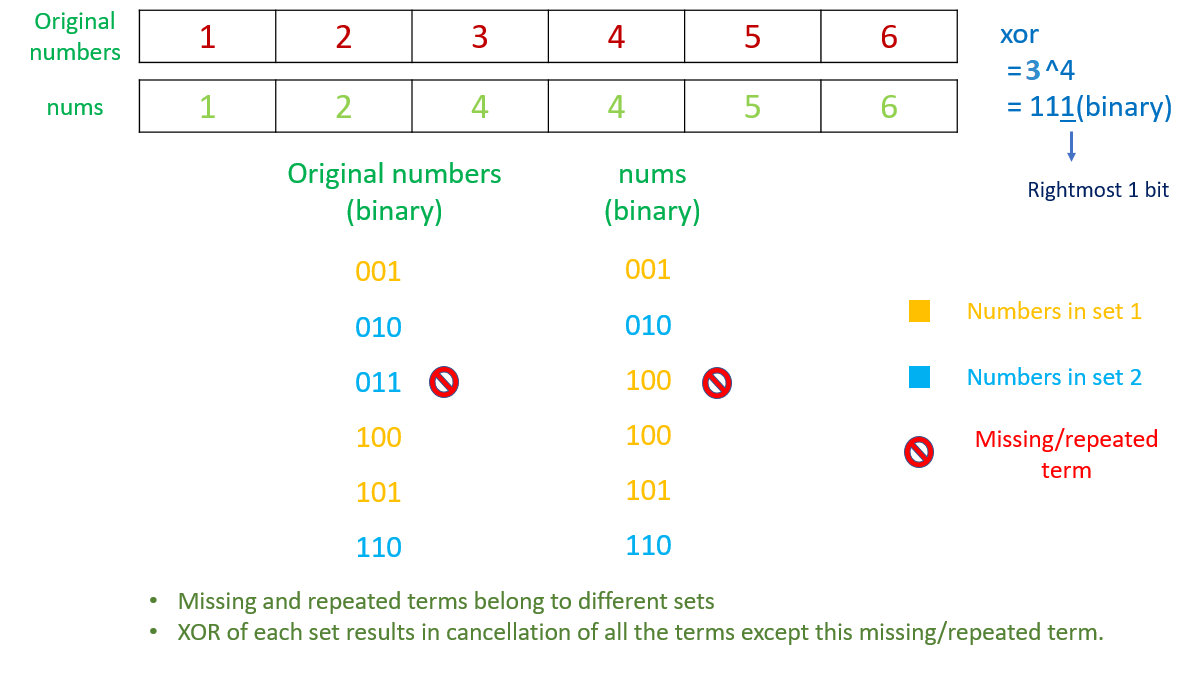
One more traversal over the can be used to identify the missing and the repeated number out of the two numbers found.
\n\nComplexity Analysis
\n- \n
- \n
Time complexity : . We iterate over elements five times.
\n \n - \n
Space complexity : . Constant extra space is used.
\n \n
\n
Analysis written by: @vinod23
\n