All leaked interview problems are collected from Internet.
552. Student Attendance Record II
Given a positive integer n, return the number of all possible attendance records with length n, which will be regarded as rewardable. The answer may be very large, return it after mod 109 + 7.
A student attendance record is a string that only contains the following three characters:
- 'A' : Absent.
- 'L' : Late.
- 'P' : Present.
A record is regarded as rewardable if it doesn't contain more than one 'A' (absent) or more than two continuous 'L' (late).
Example 1:
Input: n = 2 Output: 8 Explanation: There are 8 records with length 2 will be regarded as rewardable: "PP" , "AP", "PA", "LP", "PL", "AL", "LA", "LL" Only "AA" won't be regarded as rewardable owing to more than one absent times.
Note: The value of n won't exceed 100,000.
b'
Solution
\n\n
Approach #1 Brute Force [Time Limit Exceeded]
\nIn the brute force approach, we actually form every possible string comprising of the letters "A", "P", "L" and check if the string is rewardable by checking it against the given criterias. In order to form every possible string, we make use of a recursive gen(string, n) function. At every call of this function, we append the letters "A", "P" and "L" to the input string, reduce the required length by 1 and call the same function again for all the three newly generated strings.
!?!../Documents/552_Student_Attendance_Record_II.json:1000,563!?!
\n\nComplexity Analysis
\n- \n
- Time complexity : . Exploring combinations. \n
- Space complexity : . Recursion tree can grow upto depth and each node contains string of length . \n
\n
Approach #2 Using Recursive formulae [Time Limit Exceeded]
\nAlgorithm
\nThe given problem can be solved easily if we can develop a recurring relation for it.
\nFirstly, assume the problem to be considering only the characters and in the strings. i.e. The strings can contain only and . The effect of will be taken into account later on.
\nIn order to develop the relation, let\'s assume that represents the number of possible rewardable strings(with and as the only characters) of length . Then, we can easily determine the value of if we know the values of the counts for smaller values of . To see how it works, let\'s examine the figure below:
\n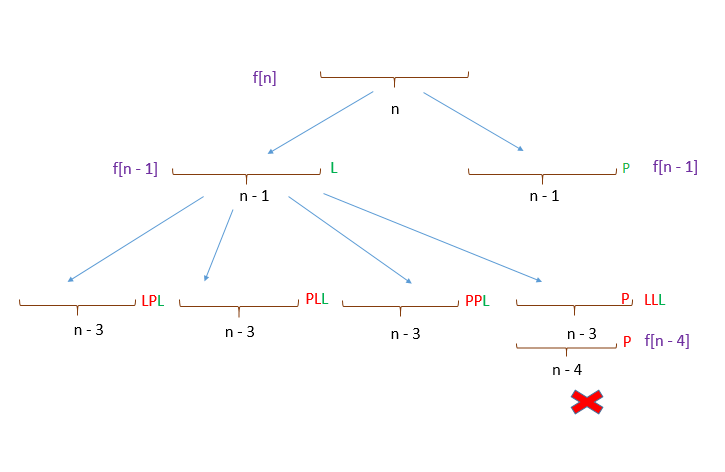
The above figure depicts the division of the rewardable string of length into two strings of length and ending with or . The string ending with of length is always rewardable provided the string of length is rewardable. Thus, this string accounts for a factor of to .
\nFor the first string ending with , the rewardability is dependent on the further strings of length . Thus, we consider all the rewardable strings of length now. Out of the four combinations possible at the end, the fourth combination, ending with a at the end leads to an unawardable string. But, since we\'ve considered only rewardable strings of length , for the last string to be rewardable at length and unawardable at length , it must be preceded by a before the .
\nThus, accounting for the first string again, all the rewardable strings of length , except the strings of length followed by , can contribute to a rewardable string of length . Thus, this string accounts for a factor of to .
\nThus, the recurring relation becomes:
\n\n\n
\nWe store all the values in an array. In order to compute , we make use of a recursive function func(n) which makes use of the above recurrence relation.
Now, we need to put the factor of character being present in the given string. We know, atmost one is allowed to be presnet in a rewardable string. Now, consider the two cases.
\n- \n
- \n
No is present: In this case, the number of rewardable strings is the same as .
\n \n - \n
A single is present: Now, the single can be present at any of the positions. If the is present at the position in the given string, in the form: "<(i-1) characters>, A, <(n-i) characters>", the total number of rewardable strings is given by: . Thus, the total number of such substrings is given by: .
\n \n
Complexity Analysis
\n- \n
- \n
Time complexity : . method will take time.
\n \n - \n
Space complexity : . array is used of size .
\n \n
\n
Approach #3 Using Dynamic Programming [Accepted]
\nAlgorithm
\nIn the last approach, we calculated the values of everytime using the recursive function, which goes till its root depth everytime. But, we can reduce a large number of redundant calculations, if we use the results obtained for previous values directly to obtain as .
\n\nComplexity Analysis
\n- \n
- \n
Time complexity : . One loop to fill array and one to calculate \n
\n \n - \n
Space complexity : . array of size is used.
\n \n
\n
Approach #4 Dynamic Programming with Constant Space [Accepted]
\nAlgorithm
\nWe can observe that the number and position of \'s in the given string is irrelevant. Keeping into account this fact, we can obtain a state diagram that represents the transitions between the possible states as shown in the figure below:
\n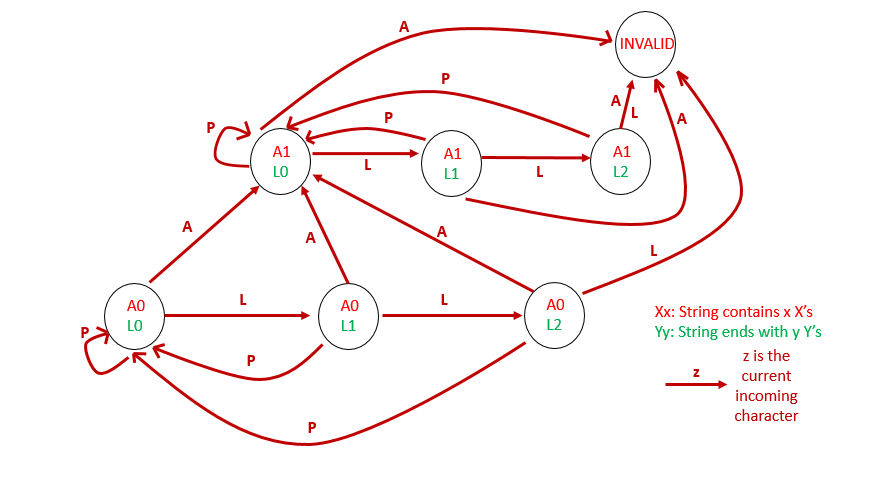
This state diagram contains the states based only upon whether an is present in the string or not, and on the number of \'s that occur at the trailing edge of the string formed till now. The state transition occurs whenver we try to append a new character to the end of the current string.
\nBased on the above state diagram, we keep a track of the number of unique transitions from which a rewardable state can be achieved. We start off with a string of length 0 and keep on adding a new character to the end of the string till we achieve a length of . At the end, we sum up the number of transitions possible to reach each rewardable state to obtain the required result.
\nWe can use variables corresponding to the states. represents the number of strings of length containing \n and ending with \n.
\nBelow code is inspired by @stefanpochmann.
\n\nComplexity Analysis
\n- \n
- \n
Time complexity : . Single loop to update the states.
\n \n - \n
Space complexity : . Constant Extra Space is used.
\n \n
\n
Approach #5 Using less variables [Accepted]
\nAlgorithm
\nIn the last approach discussed, we\'ve made use of six extra temporary variables just to keep a track of the change in the current state. The same result can be obtained by using a lesser number of temporary variables too.
\n\nComplexity Analysis
\n- \n
- \n
Time complexity : . Single loop to update the states.
\n \n - \n
Space complexity : . Constant Extra Space is used.
\n \n
\n
Analysis written by: @vinod23
\n